In today’s blog post, we look at the Azure Kubernetes Service control plane logs and how to ingest them into Azure Data Explorer. Especially, the Kubernetes Audit (kube-audit) log.

Azure Data Explorer – Ingestion Method
Looking at the export options for the Azure Kubernetes Service control plane logs we can choose between an Azure Storage Account or an Event Hub. Both solutions act as a middleware component to store data till it is ingested into Azure Data Explorer.
In our case, we choose the Azure Event Hub export option. I created the Event Hub Namespace upfront with one dedicated Event Hub with 32 partitions and enabled the auto-inflate functionality for the Event Hub throughput units.

Configure ingestion to Azure Data Explorer
Before we start to prepare everything on the Azure Data Explorer side, we configure the export of the Kubernetes Audit log to the Event Hub aks_control_plane.
Now, we begin with the Azure Data Explorer configuration. Our first step is the provisioning of a new database in our Azure Data Explorer cluster, which is called Kubernetes with the default settings.
Once created, we open the query editor to prepare the tables for the Kubernetes Audit log data.
.create table ControlPlaneLogs (
TimeGenerated: datetime, Category: string, ResourceId: string,
LogSource: string, Pod: string, ContainerId: string, LogMessage: dynamic
)
After running the command, we have our table called ControlPlaneLogs. The next table we create is called ControlPlaneLogsRawRecords and is used for the data ingestion from the aks_control_plane Event Hub.
.create table ControlPlaneLogsRawRecords (Records: dynamic)
As we do not want to store data in this table, we set the retention policy to 0.
.alter-merge table ControlPlaneLogsRawRecords policy retention softdelete = 0d
Our next step is the ingestion mapping to ensure a correct ingestion into the table.
.create table ControlPlaneLogsRawRecords ingestion json mapping 'ControlPlaneLogsRawRecordsMapping' '[{"column":"Records","Properties":{"path":"$.records"}}]'
Getting the ingested log data and monitor data into the target table ControlPlaneLogs requires a KQL function and an update policy on the table.
.create function ControlPlaneLogRecordsExpand() {
ControlPlaneLogsRawRecords
| mv-expand events = Records
| project
TimeGenerated = todatetime(events['time']),
Category = tostring(events.category),
ResourceId = tostring(events.resourceId),
LogSource = tostring(events.properties.stream),
Pod = tostring(events.properties.pod),
ContainerId = tostring(events.properties.containerID),
LogMessage = parse_json(tostring(events.properties.log))
}
The KQL function above uses the mv-expand operator to extract the different JSON values from the Records column into a new output called events. With the project operator, we map those values onto our target table structure.
You may have recognized that I transform the log property first to a string before I parse it again as JSON. Looking at the following screenshot you see that the content of the log property has escape characters.

Those escape characters prevent, that you can reference the keys directly. The next screenshot shows the difference.

.alter table ControlPlaneLogs policy update @'[{"Source": "ControlPlaneLogsRawRecords", "Query": "ControlPlaneLogRecordsExpand()", "IsEnabled": "True", "IsTransactional": true}]'
By running the above KQL command, we update the policy on our target table whenever a new record arrives in the source table ControlPlaneLogsRawRecords Azure Data Explorer executes the previously defined function and ingests the result into our target table ControlPlaneLogs.

Connect Event Hubs with Azure Data Explorer
After provisioning the table for the data ingestion, we create the necessary data connection between the Event Hub and the Azure Data Explorer database.

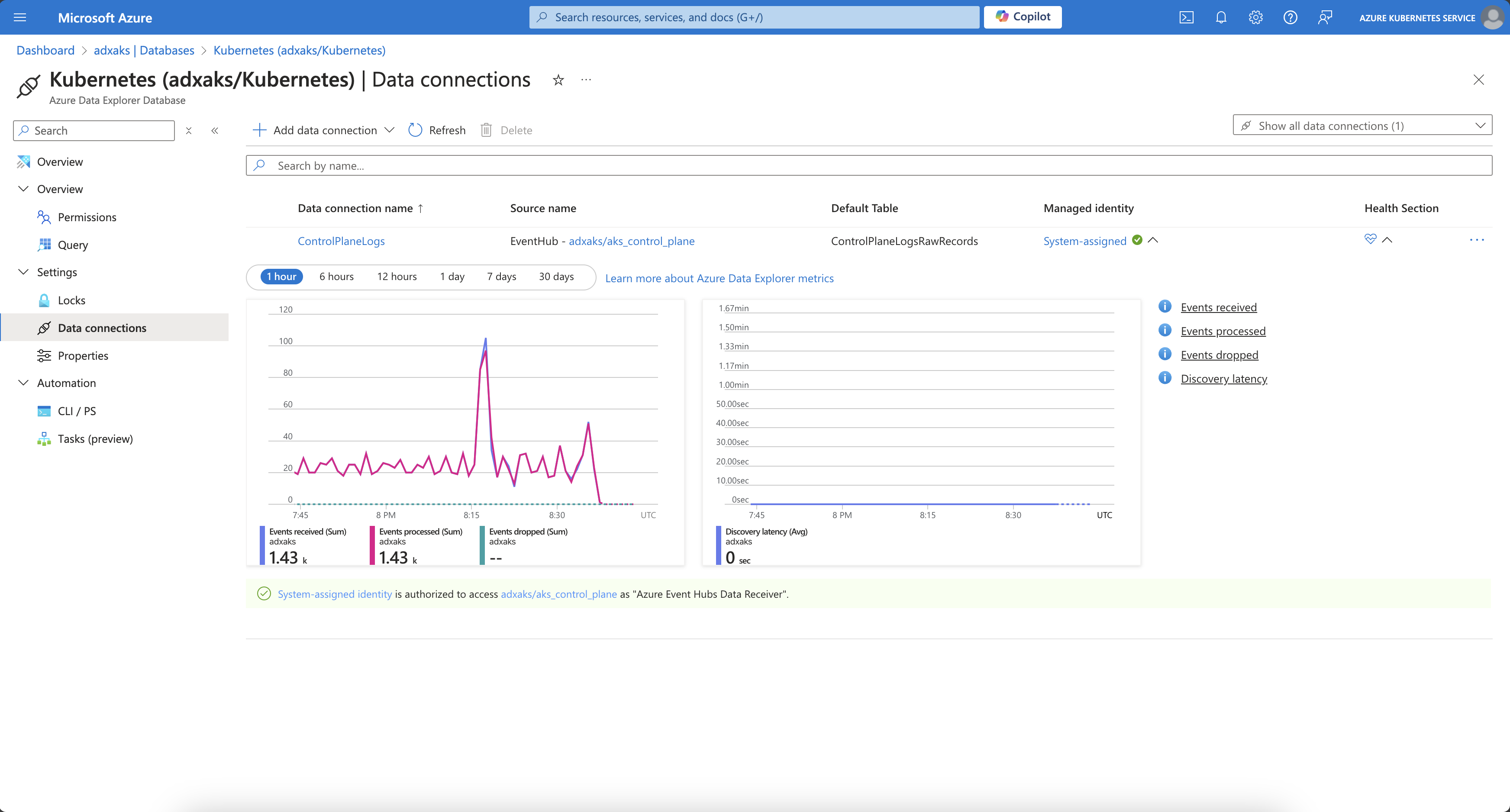
As seen in the screenshot, we provide a name for the data connection and select the appropriate Event Hub. The compression setting is kept with its default setting None. Furthermore, we provide the table name of the raw records table with the corresponding ingestion mapping. Last but not least, we select the managed identity type for the data connection. In our case, from type system-assigned.
Once the data connection has been created, we can monitor the connection and see how many events have been received and processed.
Reducing ingestion latency
Per default, our tables with the Event Hub connections use the queued ingestion method. When data is finally ingested is defined by three configuration parameters time, item, and size for the ingestion batches. The default values for those parameters are 5 minutes, 1000 items, and 1 GB. Whatever threshold is reached first triggers the final ingestion.
In the worst case, we have an ingestion latency of 5 minutes. It might be fast enough, but when we want near real-time ingestion, we either customize the batch ingestion policy or enable the streaming ingestion policy.
-> https://learn.microsoft.com/en-us/azure/data-explorer/ingest-data-overview?WT.mc_id=AZ-MVP-5000119
For the latter, streaming ingestion must be enabled on the Azure Data Explorer cluster.
We decide on the streaming ingestion policy and enable the policy on the whole Azure Data Explorer database instead of specific tables.
.alter database Kubernetes policy streamingingestion enable
Querying log and monitor data
Finally, we run our first query against the Kubernetes Audit log data.
ControlPlaneLogs
| where LogMessage.user.username == "{USER_OBJECT_ID}"
| project TimeGenerated, Cluster=split(ResourceId,"/",8)[0], Level=LogMessage.level, Stage=LogMessage.stage, IPs=LogMessage.sourceIPs,
Client=LogMessage.userAgent, Verb=LogMessage.verb, URI=LogMessage.requestURI, Status=LogMessage.responseStatus.code,
Decision=LogMessage.annotations["authorization.k8s.io/decision"], Reason=LogMessage.annotations["authorization.k8s.io/reason"]

In the screenshot above, we see the Kubernetes Audit log of the Azure Kubernetes Service cluster aks-azst-1.
The query filters on my username which is the object id and shows important information about my allowed action against the Kubernetes API server. In this specific case, I ran kubectl get nodes.
Summary
Kubernetes Audit log data can be ingested via Azure Event Hubs into an Azure Data Explorer cluster. It is indeed more effort than directly using an Azure Log Analytics workspace but depending on your needs and requirements be the better solution. Especially, for the Kubernetes Audit log it makes sense to prefer an Azure Data Explorer cluster instead of an Azure Log Analytics workspace from a cost perspective. The Kubernetes Audit log contains all events against the Kubernetes API server and can be several GB of data per day.
The example KQL file be found on my GitHub repository.