It might happen that you experience slow container image pulls on your Azure Kubernetes Service nodes. First thought might be the Azure Container Registry is the root cause. Even when using the ACR without the geo-replication option enabled, image pulls from an ACR in Europe to AKS nodes running in Australia are fast. Therefore, it can be the ACR especially when you do not use the Premium SKU as the Basic and Standard SKUs have lower values for ReadOps per minute, WriteOps per minute, and download bandwidth.
As Microsoft states in its documentation those limits are minimum estimates and ACR strives to improve performance as usage requires. Beside that you can run through the troubleshooting guide for the ACR excluding the ACR itself as the root cause.
Investigation
If it is not the container registry, what else can be the root cause for slow container image pulls on your AKS nodes?
The node itself. Especially the node’s OS disk. Depending on the VM size and the OS disk size the disk’s performance differs. Another difference is the node’s OS disk configuration whether you use ephemeral or persistent disks. For instance, an AKS node with a 128 GB OS disk running as D4s_v3 only achieves 500 IOPS and 96 MB/sec throughput using a persistent disk. The ephemeral disk option provides 8000 IOPS and 64 MB/sec throughput for this VM size.
How do we identify the OS disk as the root cause for the slow image pulls?
We look at the VMSS metrics of the particular node pool of our Azure Kubernetes Service cluster.
The OS disk queue depth metric is the most important one here.
OS Disk Queue Depth: The number of current outstanding IO requests that are waiting to be read from or written to the OS disk.
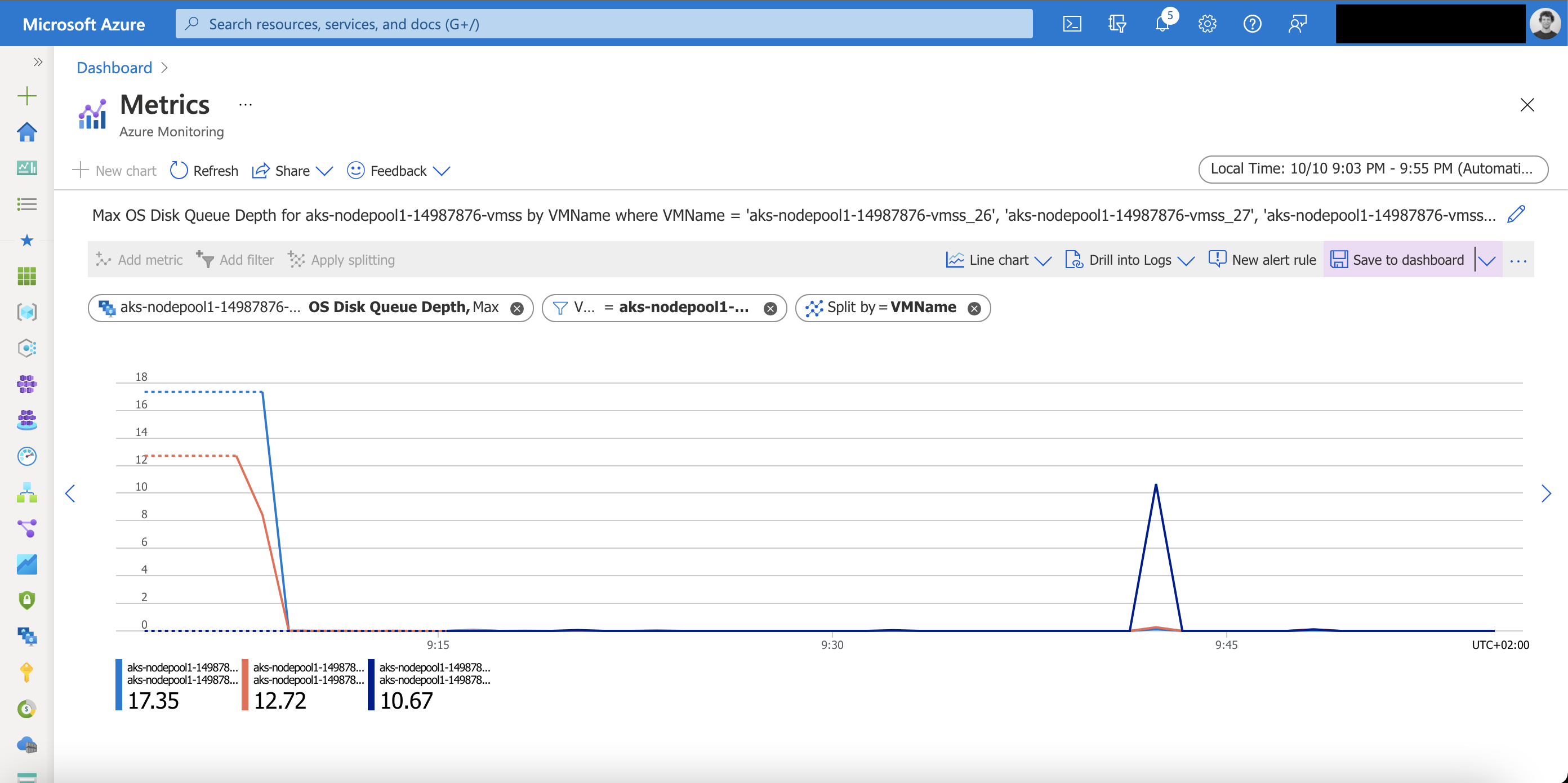
In the screenshot above you see OS disk queue depths from 10 to 17 on my AKS nodes. The first values are during the AKS cluster start as I am using the start/stop functionality for my cluster. The second peak was scaling a Kubernetes deployment from 2 to 50 replicas.
A value above 20 is a concern which you should observe and might take actions on as it indicates that the disk performance might not be enough for handling the load for container image pulls and other related disk operations.
Taking a further look into the IOPS and throughput metrics in comparison to the OS disk queue depth metric shows us which is or might become the bottleneck.
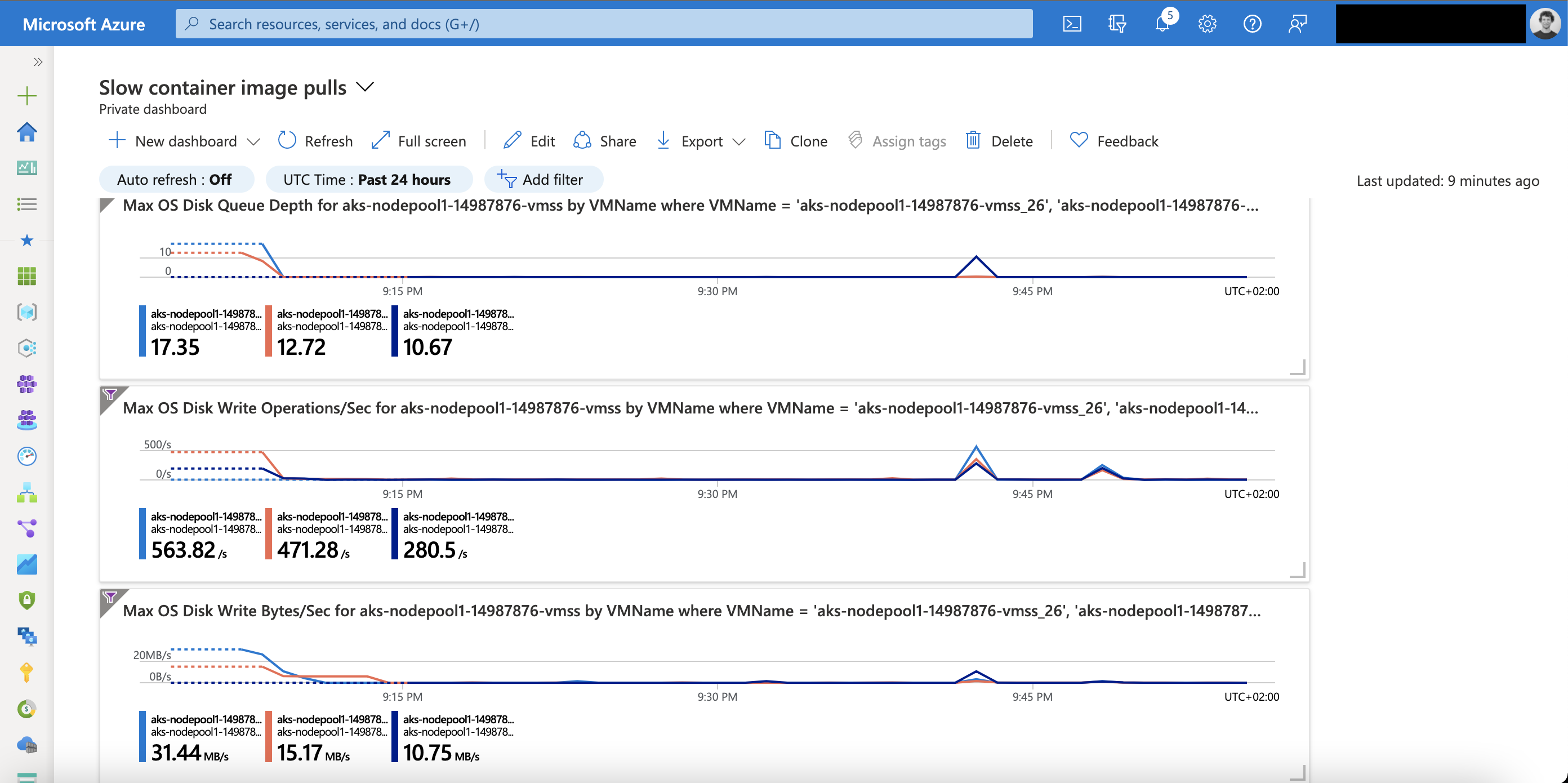
I am using ephemeral disks for my AKS nodes. Therefore, my IOPS limit is 8000 and my throughput limit is 64 MB/sec. Looking at the throughput values this might become an issue on my AKS nodes during container image pulls.
Mitigation
When do we use a larger OS disk or a larger VM size mitigating a high OS disk queue depth?
Action should be taken on that when the OS disk queue depth is constantly above 20 during normal operation of your AKS cluster. If you only see a high OS disk queue depth during an AKS cluster upgrade, a node reboot for applying security patches, or a scale-out this can be annoying but normally no action is needed. During those events, a lot of container images get pulled at the same time leading to a lot of writes, small writes, to the OS disk which in the end leads to a high OS disk queue depth.
This normally resolves itself within minutes. Should this be not the case, or this is still a concern for you then a larger OS disk or larger VM size resolves the issue.
Another option you have at your fingertips is the image pull policy setting in your Kubernetes templates. You can set it to IfNotPresent instead of Always preventing container images to be pulled which are already present on the node. The image pull policy Always instead queries every time the container registry resolving the container image digest. If the digest is different from the one of the container image in the local cache the container image gets pulled from the container registry.
Summary
It is not easy identifying the root cause for slow container image pulls on your AKS nodes as you need to dig deep into configurations and metrics. But it is a good exercise understanding your entire infrastructure configuration whether it is the container registry, the networking, or the Kubernetes nodes itself and how all works together delivering your applications to your users.