Two weeks back I participated in an incredibly good and vivid discussion on Twitter about Kubernetes CPU requests and limits. During the discussion I learned a lot and were proven that my knowledge and statement are not correct.
I had made the following statement: “CPU requests are used for scheduling but are not guaranteed at runtime.”
The first part about the scheduling is correct and the second part is simply wrong. Reflecting on the discussion, I cannot tell you how it came to this understanding. Four years ago, I read the de-facto standard book about Kubernetes “Kubernetes: Up and Running” which clearly and correctly explains it.
“With Kubernetes, a Pod requests the resources required to run its containers. Kubernetes guarantees that these resources are available to the Pod”
Kubernetes: Up & Running, Hightower, Burns, and Beda, September 2017
So, I should know it better and might have gotten confused by the following sentence from the Kubernetes docs and observations of high CPU load on Kubernetes.
“The kubelet also reserves at least the request amount of that system resource specifically for that container to use”
-> https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
How can something be reserved, set aside, for one pod and be used by another one at the same time? Let us stop here. I had at some point in time the wrong knowledge and learned it is not correct. So, I am writing this blog post to clarify how CPU requests in Kubernetes work and what I learned.
Introduction
So, what are Kubernetes CPU requests? CPU requests specify the minimum amount of compute capacity required by your application to run. You can specify CPU requests for each container in your pod. The sum of all CPU requests is then used with specified memory requests by the scheduler finding a node in the Kubernetes cluster with enough resources available.
Once the pod runs on a node its CPU requests are guaranteed / reserved.
What does guaranteed / reserved mean?
As already mentioned in the Kubernetes docs the term reserved is used and, in the book “Kubernetes: Up and Running” guaranteed. Depending on our cultural and personal understanding both words have a different meaning for us and might be contradictory to what we observe in our Kubernetes cluster.
Hence, I try to make it clearer. When pods using a CPU request and got scheduled onto a node Kubernetes provides them with an SLA (Service Level Agreement). The SLA statement between the pod and Kubernetes can be phrased like this:
“Whenever you need your CPU requests you immediately get them assigned and have them available. However, every other pod on the node can use your CPU requests as long as you do not need them by yourself.”
That is exactly how CPU requests in Kubernetes works. As long as the original pod does not need them, they are available in a pool to be used by every other pod on the node. Whenever the original pod needs its CPU requests the CPU scheduler immediately assigns the compute capacity to the pod.
Hence, CPU requests are always guaranteed at runtime.
Quod erat demonstrandum
In this example I am using the containerstack CPU stress test tool image generating constant CPU load for my four pods which will be deployed onto my three node Azure Kubernetes Service cluster.
-> https://github.com/containerstack/docker-cpustress
Each node has four cores and 16 GB memory available. According to the AKS docs a specific amount of the node resources is set aside to protect and keep the node operational.
The Kubernetes template I am using deploys all four pods onto the same node and keeps the CPU stress test running for an hour. Each pod has a CPU request of 0.5.
-> https://github.com/neumanndaniel/kubernetes/blob/master/cpu-requests/cpu-stress.yaml
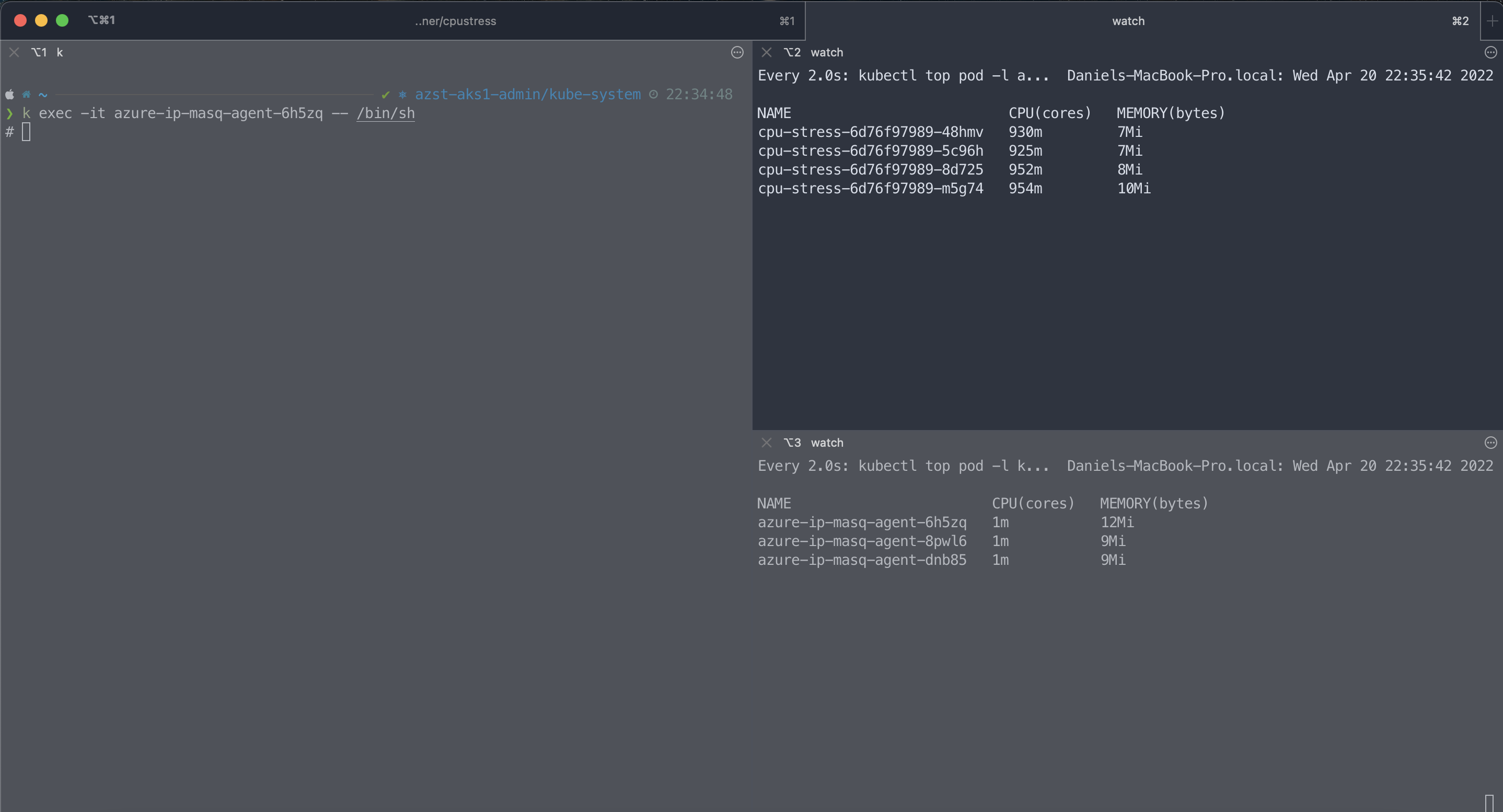
Now I need a pod which is idling around and does not use its CPU requests. As a system pod is an excellent choice I selected the azure-ip-masq-agent which CPU requests are 100m.
> kubectl resource_capacity --pod-labels k8s-app=azure-ip-masq-agent --pods NODE NAMESPACE POD CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS * * * 300m (2%) 1500m (12%) 150Mi (0%) 750Mi (1%) aks-nodepool1-14987876-vmss000026 * * 100m (2%) 500m (12%) 50Mi (0%) 250Mi (1%) aks-nodepool1-14987876-vmss000026 kube-system azure-ip-masq-agent-8pwl6 100m (2%) 500m (12%) 50Mi (0%) 250Mi (1%) aks-nodepool1-14987876-vmss000027 * * 100m (2%) 500m (12%) 50Mi (0%) 250Mi (1%) aks-nodepool1-14987876-vmss000027 kube-system azure-ip-masq-agent-dnb85 100m (2%) 500m (12%) 50Mi (0%) 250Mi (1%) aks-nodepool1-14987876-vmss000028 * * 100m (2%) 500m (12%) 50Mi (0%) 250Mi (1%) aks-nodepool1-14987876-vmss000028 kube-system azure-ip-masq-agent-6h5zq 100m (2%) 500m (12%) 50Mi (0%) 250Mi (1%)
I am using kubectl exec -it to get a terminal on the pod and then run while true; do echo; done generating a high CPU load.
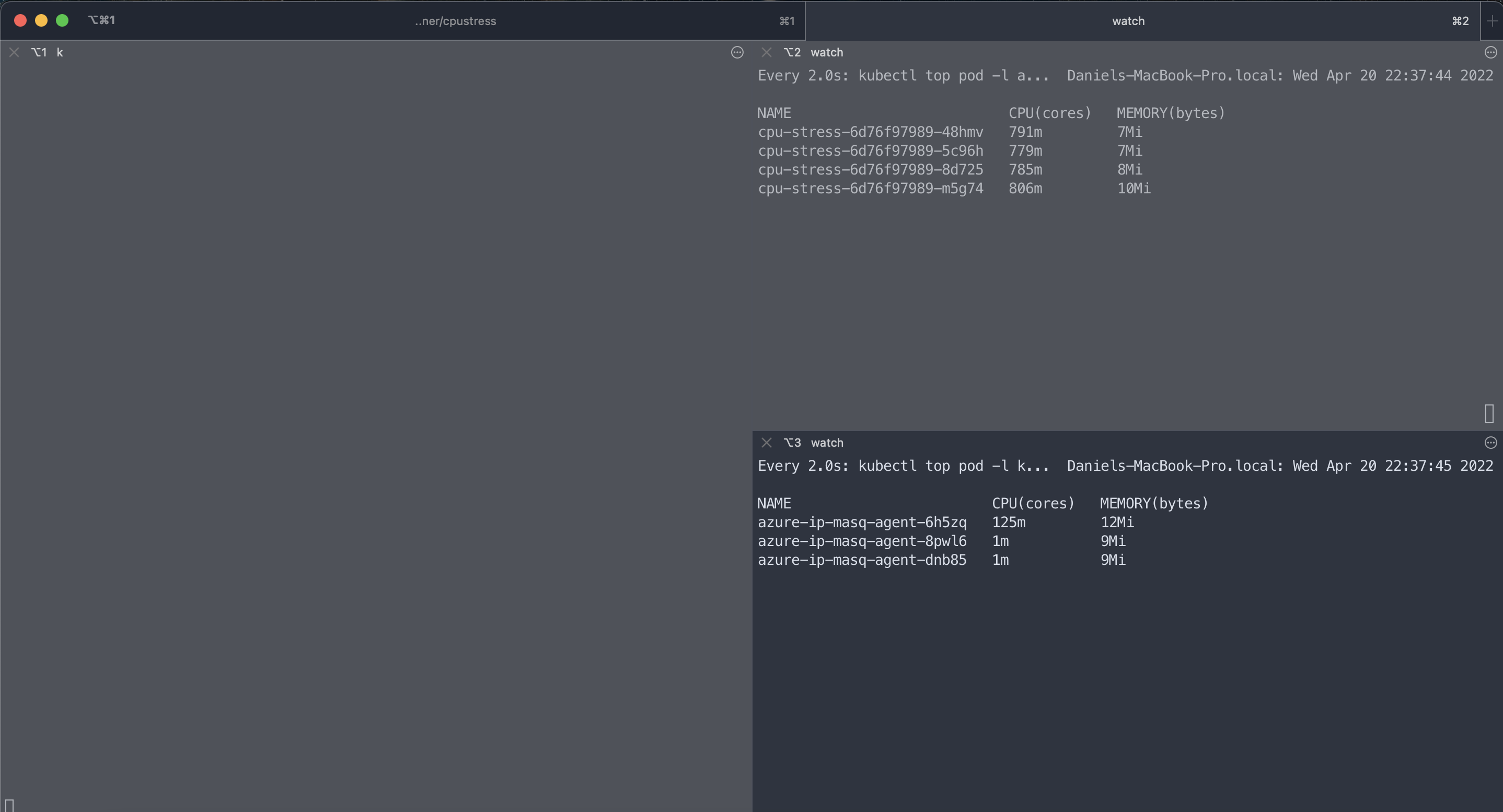
As seen above the azure-ip-masq-agent pod immediately gets at least its CPU requests assigned. In this demo a bit more which leads us to another interesting point how CPU requests work on a contended system.
CPU request behavior on contended systems
The behavior of CPU requests on contended systems is briefly explained in the Kubernetes docs.
“The CPU request typically defines a weighting. If several different containers (cgroups) want to run on a contended system, workloads with larger CPU requests are allocated more CPU time than workloads with small requests.”
When pods with different request amounts compete against each other for compute capacity Kubernetes assigns more compute capacity to the one with the higher request amount.
That said pods with a higher CPU request than other pods are given higher priority when it comes to assigning compute capacity on a contended system.
Summary
The key take-away for you is that CPU requests are used for the scheduling and guaranteed at runtime.
What this means when looking at the Quality of Service classes for pods in Kubernetes is the following:
A pod without CPU requests and limits has the QoS class BestEffort without any guarantees of receiving the needed or desired compute capacity.
Pods with CPU requests have the guarantee at any time receiving their defined requests and are able to run your application with its minimal desires. The QoS class here is Burstable.
When you need a guarantee that at any given time your application can get the compute capacity it needs to deliver the best performance you have two options:
- Set the pod’s CPU request high enough which results again in the QoS class Burstable.
- Set the pod’s CPU requests and limits to the same value or only set the limits. Then the pod gets the QoS class Guaranteed
I hope I shed some light on how CPU requests work on Kubernetes. An interesting follow-up read on this topic is about why you should not specify CPU limits.
-> https://home.robusta.dev/blog/stop-using-cpu-limits/
As always in IT the answer is it depends on. Finally, ensure at least you use CPU requests.