This is the last blog post of a series of posts covering the topic about increasing the application availability on Azure Kubernetes Service / Kubernetes.
Today we cover the pod topology spread constraints.
What are pod topology spread constraints?
In the first post of the series, I talked about the pod disruption budget. The PDB guarantees that a certain amount of your application pods is available.
The last post covered pod anti-affinity settings distributing the application pods across different nodes in your Kubernetes cluster.
Pod topology spread constraints are like the pod anti-affinity settings but new in Kubernetes. They were promoted to stable with Kubernetes version 1.19.
So, what are pod topology spread constraints? Pod topology spread constraints controlling how pods are scheduled across the Kubernetes cluster. They rely on failure-domains like regions, zones, nodes, or custom defined topology domains which need to be defined as node labels.
Using the pod topology spread constraints setting
You can choose between two ways of specifying the topology spread constraints. On pod-level or on cluster-level. Both ways have the same three settings: maxSkew, topologyKey and whenUnsatisfiable.
On pod-level you must additionally specify the labelSelector setting which in contrast is calculated automatically on cluster-level using the information from services, replication controllers, replica sets or stateful sets a pod belongs to.
Let us have a look at the different settings except the labelSelector and topologyKey setting as they are well-known.
The whenUnsatisfiable setting is the easiest one. What should happen with a pod when the pod does not satisfy the topology spread constraints? You can choose between DoNotSchedule, which is the default, or ScheduleAnyway.
In favor of keeping your application high available I recommend ScheduleAnyway. Even this means that pods can land on the same node in the same availability zone under rare circumstances.
The maxSkew setting defines the allowed drift for the pod distribution across the specified topology. For instance, a maxSkew setting of 1 and whenUnsatisfiable set to DoNotSchedule is the most restrictive configuration. Defining a higher value for maxSkew leads to a more non-restrictive scheduling of your pods. Which might be not the result you want.
To guarantee high availability and max scheduling flexibility of your application maxSkew should be 1 and whenUnsatisfiable should be ScheduleAnyway.
This combination ensures that the scheduler gives higher precedence to topologies that help reducing the skew. But will not led to pods in pending state that cannot satisfy the pod topology spread constraints due to the maxSkew setting.
Enabling pod topology spread constraints
On a managed Kubernetes cluster like Azure Kubernetes Service, you cannot use the cluster-level configuration unfortunately. The required apiVersion and kind are not exposed to be customizable by the end user. Therefore, we only can set pod topology spread constraints on the pod-level itself.
Let us have a look at the following example.
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
...
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: go-webapp
containers:
...
In the template I set the setting to my already mentioned recommendations. After applying the template to my AKS cluster with three nodes in three different availability zones the application pods are distributed evenly across all three zones.
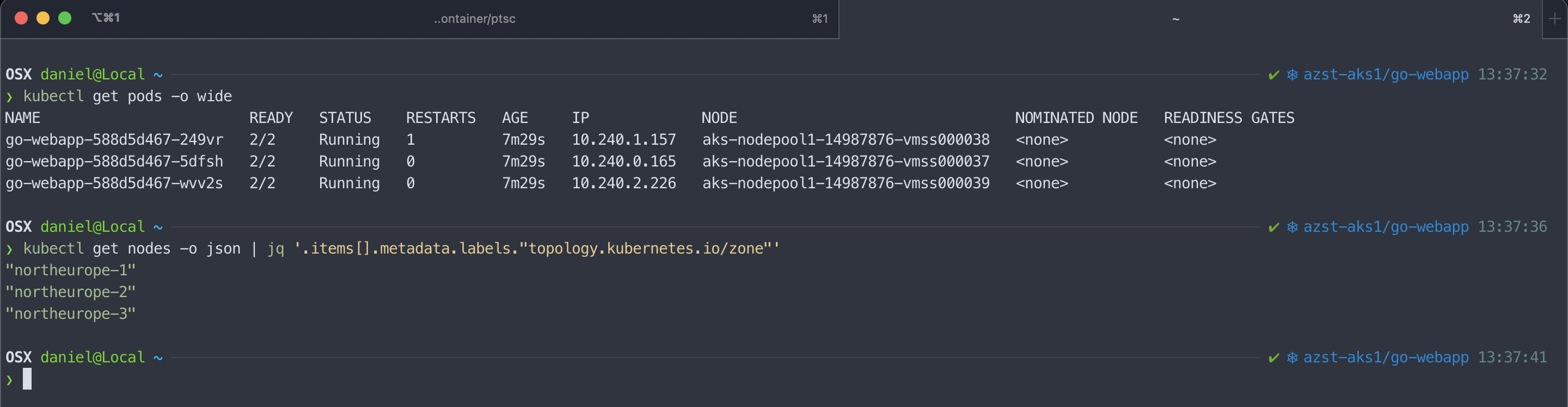
Adjusting the replica number to five spins up the two additional pods also across the availability zones.
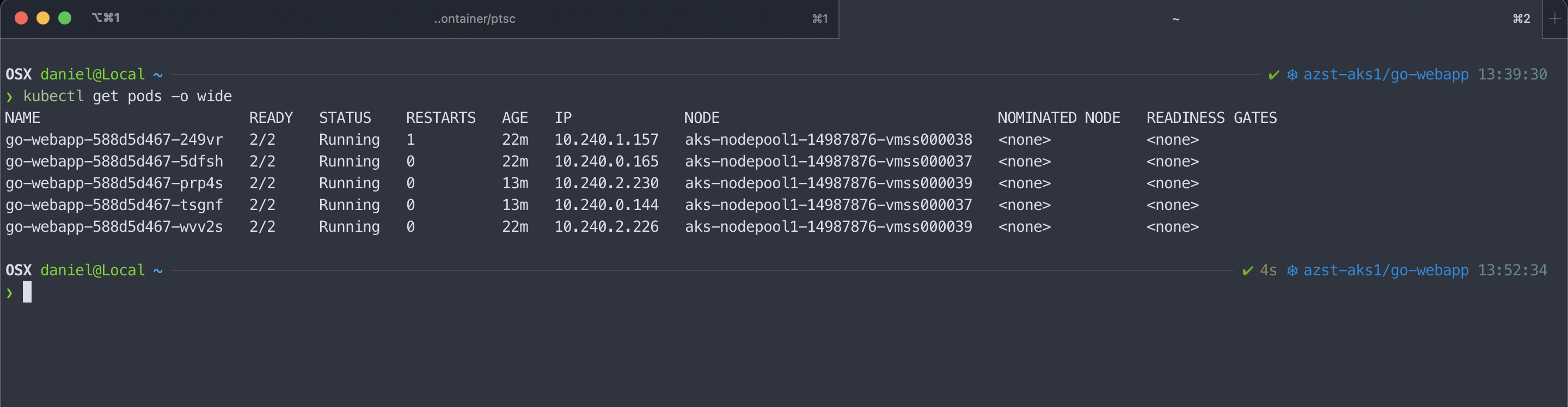
Beside defining only a single topology spread constraint you are also able to specify multiple ones.
You find more details and examples for pod topology spread constraints in the Kubernetes documentation.
-> https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/
What protection provides the pod topology spread constraints setting?
The pod topology spread constraints provide protection against zonal or node failures for instance whatever you have defined as your topology. It is like the pod anti-affinity which can be replaced by pod topology spread constraints allowing more granular control for your pod distribution.
Summary
Pod topology spread constraints are one of the latest feature sets in Kubernetes helping you to run highly available applications.
Compared to the pod anti-affinity setting pod topology spread constraints gives you better control about the pod distribution across the used topology.
Therefore, I recommend the usage of pod topology spread constraints on Kubernetes clusters with version 1.19 or higher.